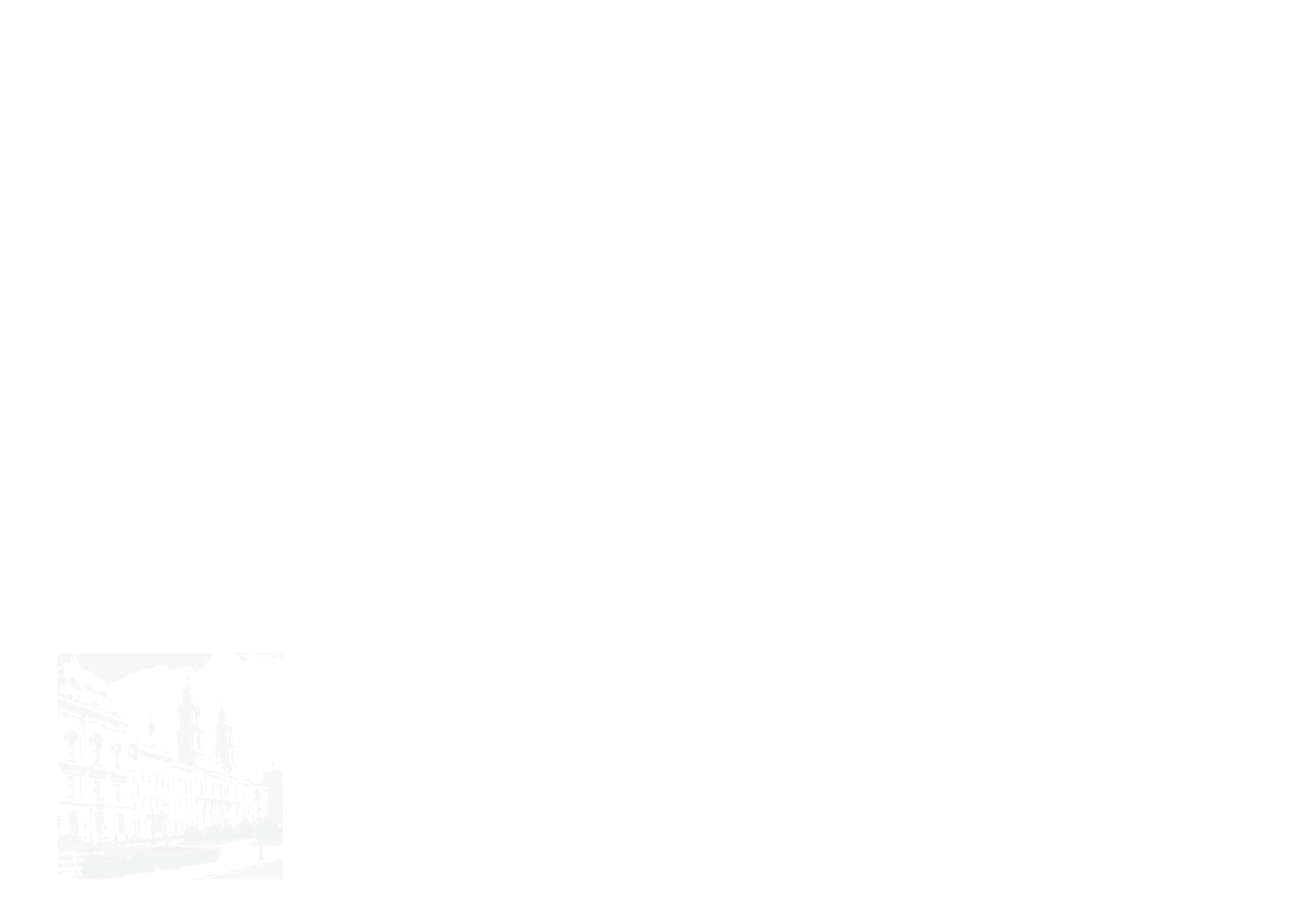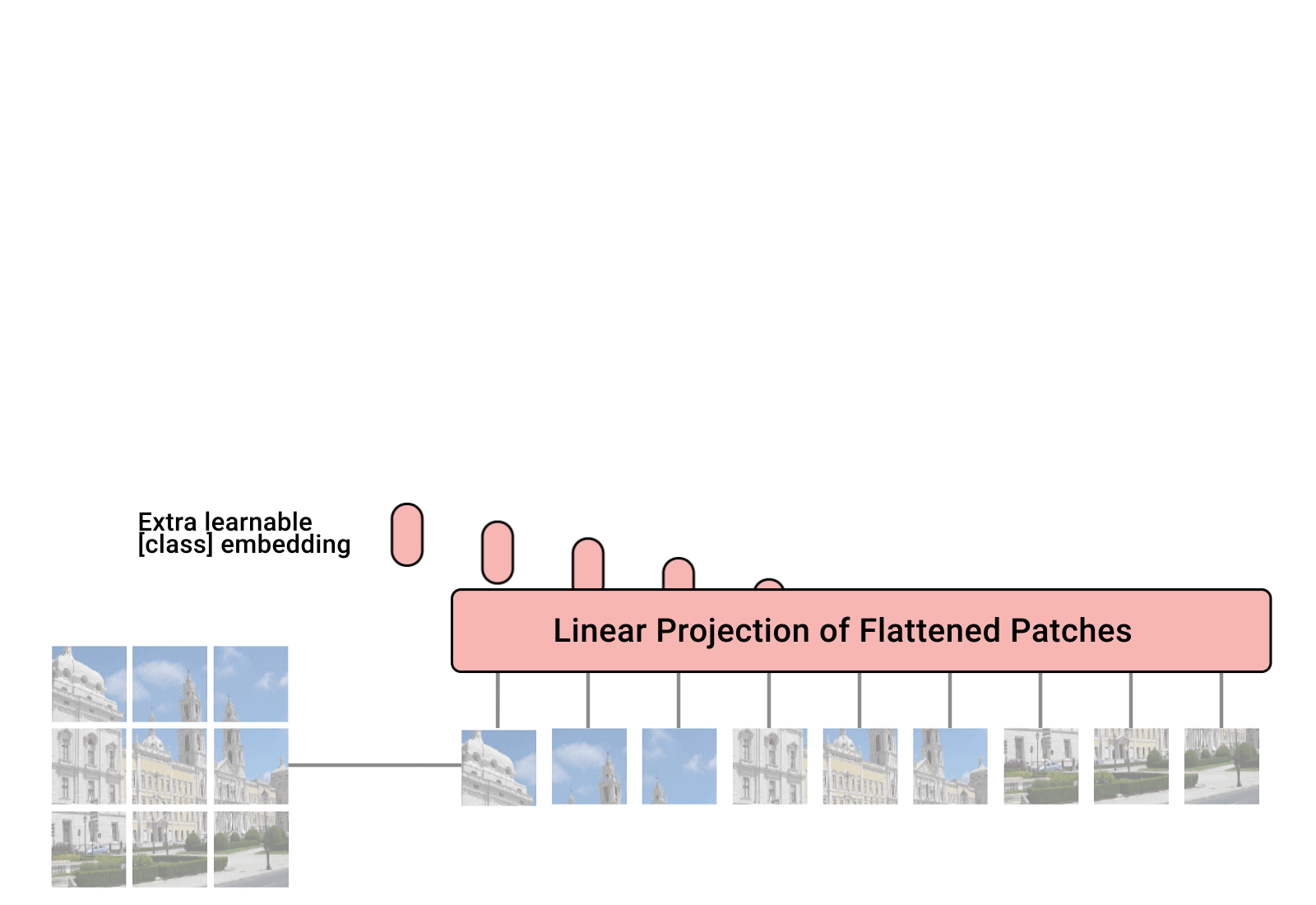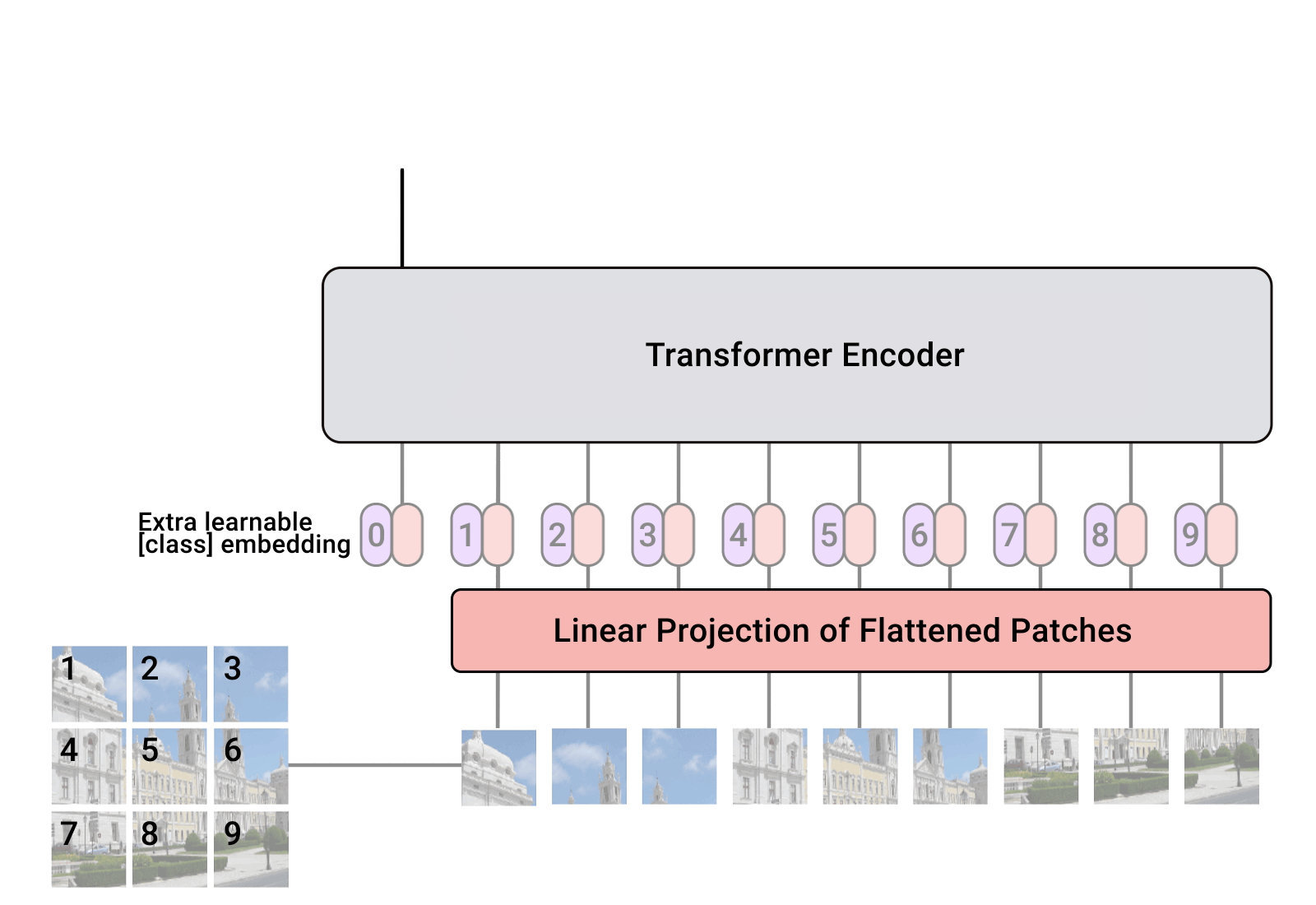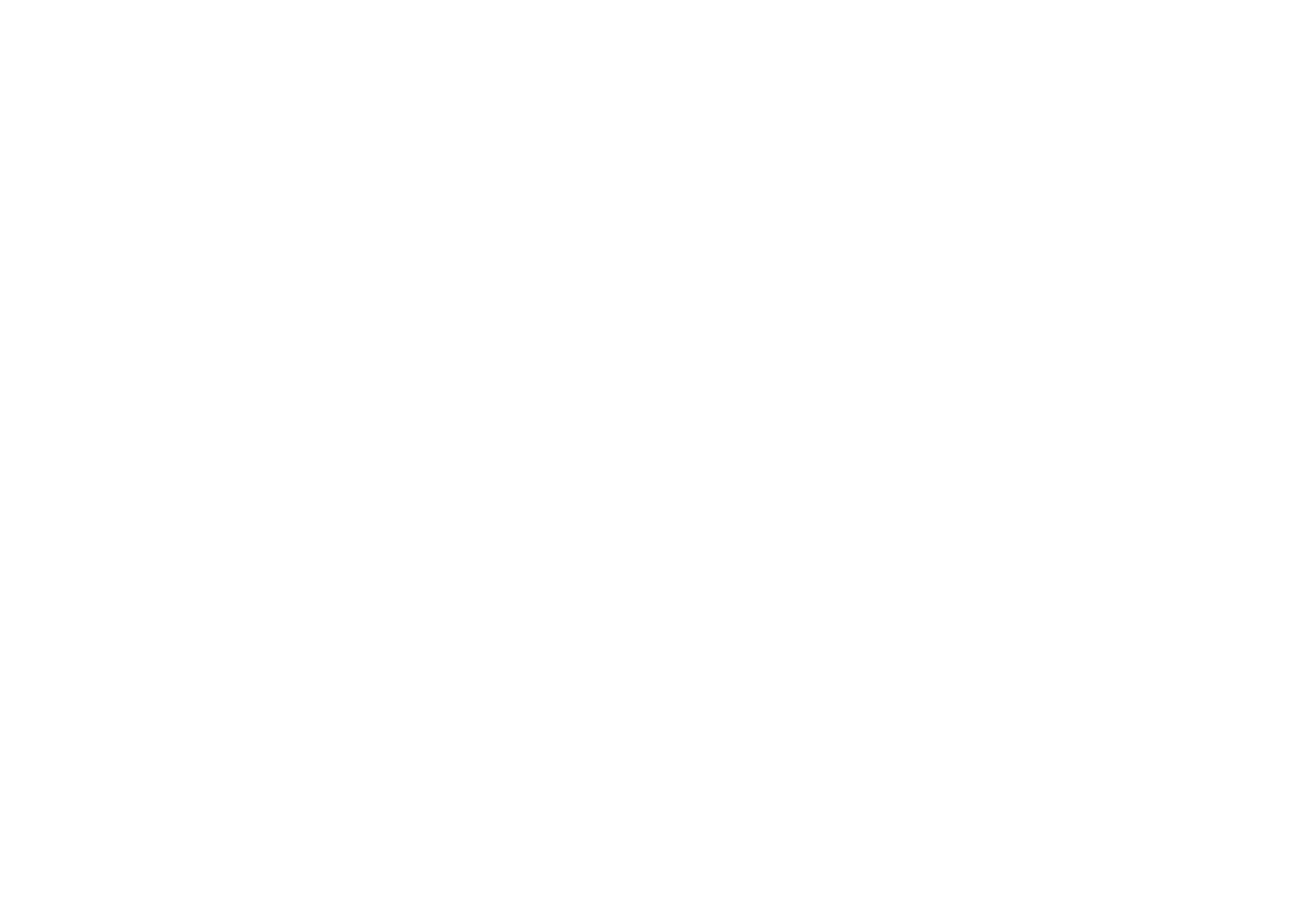1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim=512, num_heads=8):
super(Attention, self).__init__()
self.num_heads = num_heads
self.scale = dim ** -0.5
assert dim % self.num_heads == 0
self.qkv = nn.Linear(dim, dim * 3, bias=False)
self.fc = nn.Sequential(
nn.Linear(512, 512),
nn.Dropout(0.1),
)
def forward(self, x):
qkv = self.qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.num_heads), qkv)
attn = torch.einsum('bhid,bhjd->bhij', q, k) * self.scale
attn = attn.softmax(dim=-1)
out = torch.einsum('bhij,bhjd->bhid', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.fc(out)
return out
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, mlp_dim, dropout):
super(Transformer, self).__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Residual(PreNorm(dim, Attention(dim, num_heads=heads, dropout=dropout))),
Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout=dropout)))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x)
x = ff(x)
return x
|