编写自己的一个操作系统(Github)
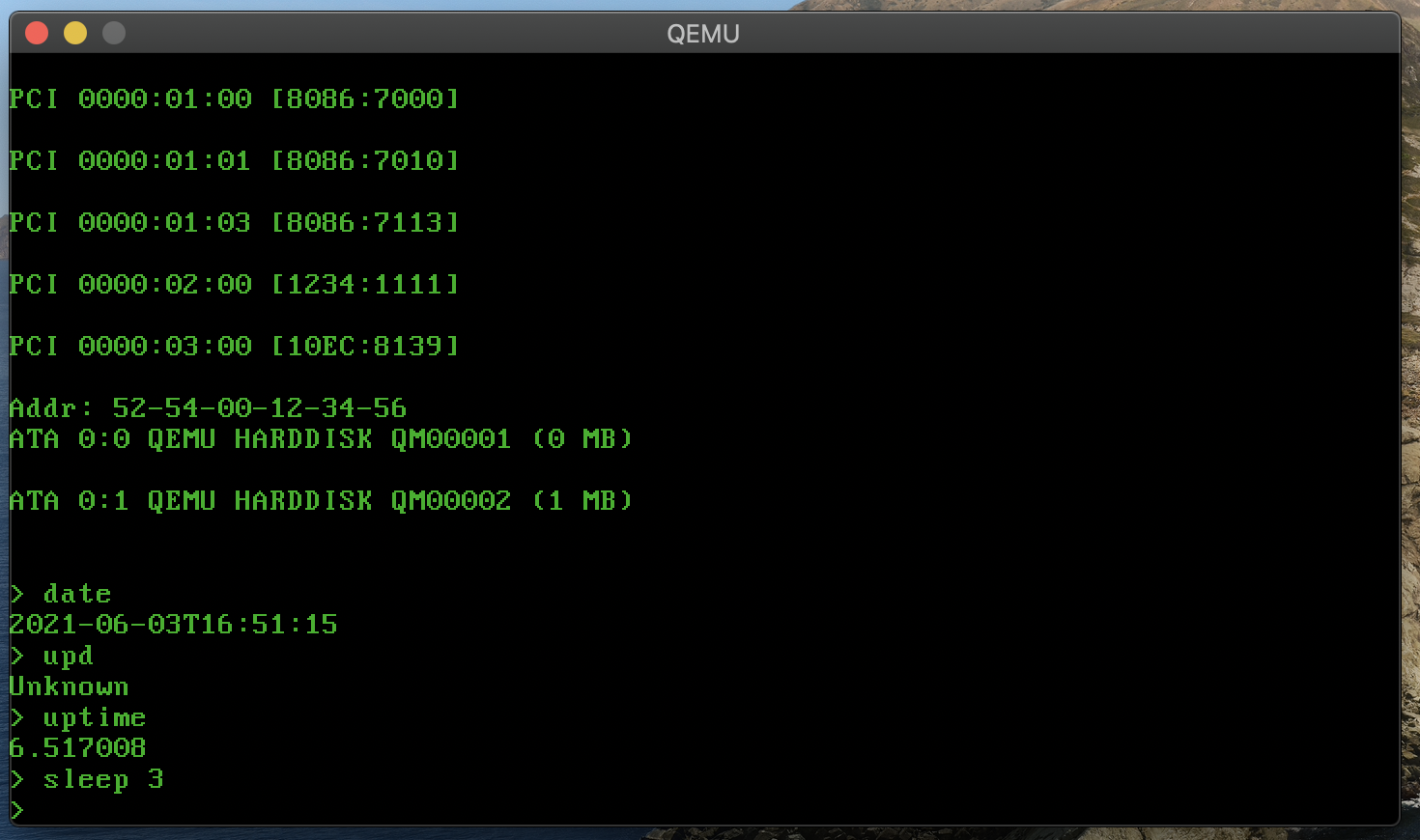
代码统计为
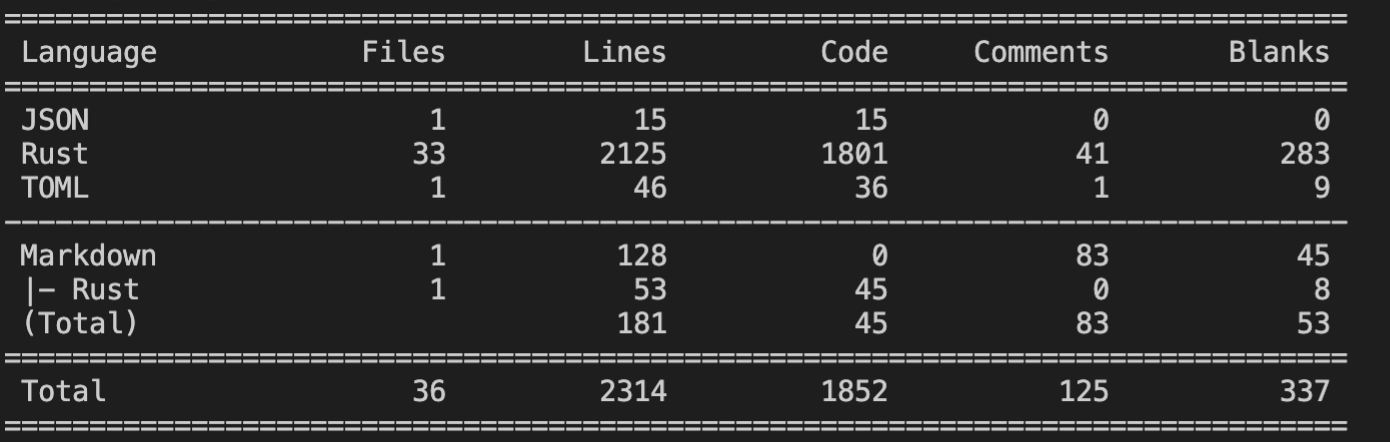
其中Rust代码量为2125行,好像也不是很多
编写自己的一个操作系统是非常有趣,从底层到顶层的一步一步地搭建,这个过程痛苦但是非常有意思,整个操作系统的搭建离不开两个字抽象,都知道计算机内部的表示都是01,单独的01是没有意义的,但是如果将01组合起来并放在上下文中,就体现01的意义。比如ASCII
 ASCII表中每一个字符都是8位bit,一共表示了128个字符,有些字符可以打印,而有些字符不可以打印,赋予不同的含义。而字符是怎么打印到屏幕呢?那就需要显示方面的支持,下面会一一介绍。当赋予了01各种各样的含义,操作系统对01不同的功能进行封装,也就是系统内核的抽象,这些都是非常大的工程。编写一个操作系统有以下几个步骤
ASCII表中每一个字符都是8位bit,一共表示了128个字符,有些字符可以打印,而有些字符不可以打印,赋予不同的含义。而字符是怎么打印到屏幕呢?那就需要显示方面的支持,下面会一一介绍。当赋予了01各种各样的含义,操作系统对01不同的功能进行封装,也就是系统内核的抽象,这些都是非常大的工程。编写一个操作系统有以下几个步骤
- 内核启动
- 打印字符
- 中断(各种中断)
- 分页(物理存储分配)
- 内存分配(堆与栈内存的分配)
- 线程
- 文件系统
- 总线
- 网络
- shell
其中中断、分页、内存分配是操作系统的核心,直接决定了操作系统是如何运转的。
0. 内核启动
操作系统本质上就是运行在一台机器上的程序,当机器启动就一直在运行,因此是无限循环的、一直开着的机器,在这机器中通过各种外设进行干预,从而实现了计算机的工作流程。一个简单的内核就是一个while循环的命令,使得机器一直开着,不能接受其他的任何操作。当机器启动的时候,就会开机自动检查,首先从给定的镜像文件中读取数据到机器的启动项中,然后执行我们烧写的系统命令。这一步启动一般采用GRUB,GRUB称之为GNU project’s bootloader,是一种规范性的电脑启动标准,大部分计算机启动就是这种规范。后来发展了UEFI。在我写的内核代码中主要是下面的一段代码
1
2
3
4
5
6
7
8
9
10
11
|
entry_point!(kernel_main);
#[panic_handler]
fn panic(_info: &PanicInfo) -> ! {
loop {}
}
fn kernel_main(boot_info: &'static BootInfo) -> ! {
loop {
}
}
|
通过入口进入kernel_main,然后让机器启动进入死循环,在这里我们啥也没有做,因此是一个简单的内核系统,没有什么功能,就是一个永久运行的机器而已。
1. 打印字符到屏幕
从这一步开始就进入到了操作系统核心的编写路程。首先我们需要能够看到操作系统发生了什么,如果不知道那怎么调试呢?因此计算机方面的人员首先采用VGA, VGA显示器是一个非常简单的显示模型,能够将ASCII中的可打印字符全部打印出来,因此早期的计算机首先采用这种方式来进行打印。那么如何打印? 硬件开发初始就已经设定了开关,通过设置电路从而使得打印成为可能。比如一个64位的字符,操作电路能够展示出不同的字符出来,那么计算机如何操作这些电路的呢? 在VGA启动初期,就将自己的硬件地址写入到存储中,当你在规定的地址上写入数值的时候,那么就会将数据写入到硬件地址上。
1
2
3
4
5
|
pub static ref WRITER: Mutex<Writer> = Mutex::new(Writer {
column_position: 0,
color_code: ColorCode::new(Color::Green, Color::Black),
buffer: unsafe { &mut *(0xb8000 as *mut Buffer) },
});
|
这里的0xb8000就是VGA的操作地址。还有一种方式就是操作端口,但是一般不用,都是直接使用操作地址来操作VGA显示。(There are generally two ways to access VGA text-mode for an application: through the Video BIOS interface or by directly accessing video RAM[4] and I/O ports. The latter method is considerably faster, and allows quick reading of the text buffer, for which reason it is preferred for advanced TUI programs.)
在这里0xb8000就是对应的物理地址,直接操作了VGA的显示。这种方式是最高效的操作设备的方法,称之为DMA,一般来说不允许这样操作,因为操作错误的地址容易引起系统的崩溃,因此安全一般操作虚拟内存,然后通过虚拟内存映射到真实的物理地址。虚拟内存是内存分配中的内容。
2. 中断(各种中断)
在计算机系统中,中断是一个非常重要的机制,因为有了中断,才使得计算机的操作多样性,能够使得计算机接受外部的信号、时间信号以及其他各种信号。想象一下如果没有中断,一个计算机程序必须要运行完才能运行下一个程序,如果突然来了一个紧急的程序,那么就需要等待,因此大大降低了计算机的性能。在x86系统中,称之为Interrupt Request (IRQ) or Hardware Interrupt,一共定义了16个中断,分别是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
IRQ Description
0 Programmable Interrupt Timer Interrupt
1 Keyboard Interrupt
2 Cascade (used internally by the two PICs. never raised)
3 COM2 (if enabled)
4 COM1 (if enabled)
5 LPT2 (if enabled)
6 Floppy Disk
7 LPT1 / Unreliable "spurious" interrupt (usually)
8 CMOS real-time clock (if enabled)
9 Free for peripherals / legacy SCSI / NIC
10 Free for peripherals / SCSI / NIC
11 Free for peripherals / SCSI / NIC
12 PS2 Mouse
13 FPU / Coprocessor / Inter-processor
14 Primary ATA Hard Disk
15 Secondary ATA Hard Disk
|
这些表达了x86支持的中断类型,比如第一个就是时间中断,第二个就是键盘中断,时间中断用来控制程序的切换以及其他功能,键盘中断能够使得程序进行中能够接受外部的信号,这样就可以进行人机交互,中断的定义如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
pub static ref IRQ_HANDLERS: Mutex<[fn(); 16]> = Mutex::new([default_handler; 16]);
static ref IDT: InterruptDescriptorTable = {
let mut idt = InterruptDescriptorTable::new();
idt.breakpoint.set_handler_fn(breakpoint_handler);
unsafe {
idt.double_fault
.set_handler_fn(double_fault_handler)
.set_stack_index(kernel::gdt::DOUBLE_FAULT_IST_INDEX);
}
idt[interrupt_index(0) as usize].set_handler_fn(irq0_handler);
idt[interrupt_index(1) as usize].set_handler_fn(irq1_handler);
idt[interrupt_index(2) as usize].set_handler_fn(irq2_handler);
idt[interrupt_index(3) as usize].set_handler_fn(irq3_handler);
idt[interrupt_index(4) as usize].set_handler_fn(irq4_handler);
idt[interrupt_index(5) as usize].set_handler_fn(irq5_handler);
idt[interrupt_index(6) as usize].set_handler_fn(irq6_handler);
idt[interrupt_index(7) as usize].set_handler_fn(irq7_handler);
idt[interrupt_index(8) as usize].set_handler_fn(irq8_handler);
idt[interrupt_index(9) as usize].set_handler_fn(irq9_handler);
idt[interrupt_index(10) as usize].set_handler_fn(irq10_handler);
idt[interrupt_index(11) as usize].set_handler_fn(irq11_handler);
idt[interrupt_index(12) as usize].set_handler_fn(irq12_handler);
idt[interrupt_index(13) as usize].set_handler_fn(irq13_handler);
idt[interrupt_index(14) as usize].set_handler_fn(irq14_handler);
idt[interrupt_index(15) as usize].set_handler_fn(irq15_handler);
idt
};
|
这里定义了16个中断,比如实现第一个中断将产生中断后发生的动作用一个函数来表示
时间中断
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
macro_rules! irq_handler {
($handler:ident, $irq:expr) => {
pub extern "x86-interrupt" fn $handler(_stack_frame: InterruptStackFrame) {
let handlers = IRQ_HANDLERS.lock();
handlers[$irq]();
unsafe {
PICS.lock().notify_end_of_interrupt(interrupt_index($irq));
}
}
};
}
pub fn set_irq_handler(irq: u8, handler: fn()) {
interrupts::without_interrupts(|| {
let mut handlers = IRQ_HANDLERS.lock();
handlers[irq as usize] = handler;
clear_irq_mask(irq);
});
}
pub fn pit_interrupt_handler() {
println!(".");
}
|
在这里定义了一个时间中断函数,如果每次时间中断就会打印一个.,时间中断中包含pit、rtc这是两种不同的时间中断,第一个是可编程控制程序的中断Programmable Interval Timer(PIT),第二个中断是读取Real-Time Clock(RTC)上真实时间以后的中断。
- PIT中断是用来计数来控制时间的编程
- RTC中断真实时间的控制系统,当计算机启动,先从BIOS上读取真实的时间时间,然后读取到系统中开始计时,核心代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
|
pub fn rtc(&mut self) -> RTC {
while self.is_updating() {
x86_64::instructions::hlt();
}
let mut second = self.read_register(Register::Second);
let mut minute = self.read_register(Register::Minute);
let mut hour = self.read_register(Register::Hour);
let mut day = self.read_register(Register::Day);
let mut month = self.read_register(Register::Month);
let mut year = self.read_register(Register::Year) as u16;
let b = self.read_register(Register::B);
|
读取到时间以后就可以通过编程来得到时间以及各种地区的时间转换。
键盘中断
通过键盘中断能够使得人机交互成为可能。键盘的字符主要是通过IO端口来读取的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
fn read_scancode() -> u8 {
let mut port = Port::new(0x60);
unsafe { port.read() }
}
pub fn interrupt_handler() {
let mut keyboard = KEYBOARD.lock();
let scancode = read_scancode();
if let Ok(Some(key_event)) = keyboard.add_byte(scancode) {
if let Some(key) = keyboard.process_keyevent(key_event) {
let c = match key {
DecodedKey::Unicode(c) => c,
DecodedKey::RawKey(KeyCode::ArrowLeft) => '←', // U+2190
DecodedKey::RawKey(KeyCode::ArrowUp) => '↑', // U+2191
DecodedKey::RawKey(KeyCode::ArrowRight) => '→', // U+2192
DecodedKey::RawKey(KeyCode::ArrowDown) => '↓', // U+2193
DecodedKey::RawKey(_) => {
return;
}
};
kernel::console::key_handle(c);
// print!("{}", c);
}
}
}
|
3. 分页(物理存储分配)
在操作系统中一个重要的功能就是将各个程序的操作空间区分开来,避免相互影响防止导致系统的崩溃。比如浏览器的进程不会影响到听歌的进程,因此对程序进行隔离是非常重要的,在这种情况下的计算机系统也称之为保护模式,即用户的进程不会影响到操作系统的进程。在很久之前科学家就提出了Virtual Memory,用来管理真实的物理内存,通过虚拟内存的映射,来指向真实内存的地址,从而实现对真实内存的操作,而不会影响其他程序的正常工作。一个典型的虚拟内存
 从图中可以看到虚拟内存对应的物理内存空间。但是这样有一个问题那就是不利于内存的管理,为什么这么说当已经分配了一个非常大的内存之后,但是物理内存中有很多空闲的空间,无法被充分利用起来,要知道计算机中的cpu以及内存资源是非常紧张的,因此不能被浪费,于是科学家就提出了
从图中可以看到虚拟内存对应的物理内存空间。但是这样有一个问题那就是不利于内存的管理,为什么这么说当已经分配了一个非常大的内存之后,但是物理内存中有很多空闲的空间,无法被充分利用起来,要知道计算机中的cpu以及内存资源是非常紧张的,因此不能被浪费,于是科学家就提出了Page这个概念。如图所示
 通过将虚拟内存以及真实内存进行一小块一小块分割(虚拟内存中叫page、真实内存中叫frames)从而实现虚拟内存到真实内存的映射。那么如何建立这种映射呢?那就是Page Table。
通过将虚拟内存以及真实内存进行一小块一小块分割(虚拟内存中叫page、真实内存中叫frames)从而实现虚拟内存到真实内存的映射。那么如何建立这种映射呢?那就是Page Table。
Page Tables
Page Tables是一个虚拟内存到物理实际内存的一个映射表,如下图所示
 可以看到虚拟内存的大小以及对应的frame在哪里。每一个程序开始运行的时候都会有一个页表,那么怎么知道第一个页表呢? 那就是CR3这个寄存器,当程序开始运行的时候,第一步读取CR3寄存器中的值,然后找到对应的表,然后开始一级一级往下映射。在现代操作系统中,不会只有一级表的,因为一级表会大量浪费空间,以及寻址时间。因此发展了级联表
可以看到虚拟内存的大小以及对应的frame在哪里。每一个程序开始运行的时候都会有一个页表,那么怎么知道第一个页表呢? 那就是CR3这个寄存器,当程序开始运行的时候,第一步读取CR3寄存器中的值,然后找到对应的表,然后开始一级一级往下映射。在现代操作系统中,不会只有一级表的,因为一级表会大量浪费空间,以及寻址时间。因此发展了级联表
 在x86_64系统中,有4级页表
在x86_64系统中,有4级页表
 (We see that each table index consists of 9 bits, which makes sense because each table has 2^9 = 512 entries. The lowest 12 bits are the offset in the 4KiB page (2^12 bytes = 4KiB). Bits 48 to 64 are discarded, which means that x86_64 is not really 64-bit since it only supports 48-bit addresses.)
因此,目前的x86_64并不是真正意义上的64位,因此目前只支持48位寻址。
从CPU的角度来说,一旦MMU打开了,它执行的每条指令中的地址都是虚拟内存地址。
(We see that each table index consists of 9 bits, which makes sense because each table has 2^9 = 512 entries. The lowest 12 bits are the offset in the 4KiB page (2^12 bytes = 4KiB). Bits 48 to 64 are discarded, which means that x86_64 is not really 64-bit since it only supports 48-bit addresses.)
因此,目前的x86_64并不是真正意义上的64位,因此目前只支持48位寻址。
从CPU的角度来说,一旦MMU打开了,它执行的每条指令中的地址都是虚拟内存地址。
寻址过程
首先计算机或者程序启动从CR3得到最顶层的页表映射,然后找第4级物理地址,找第三级,一直到第一级物理地址,从而映射到真实的物理地址
 如图所示,在程序中代码如下
如图所示,在程序中代码如下
1
2
3
4
5
6
7
8
9
|
pub unsafe fn active_level_4_table(physical_memory_offset: VirtAddr) -> &'static mut PageTable {
use x86_64::registers::control::Cr3;
let (level_4_table_frame, _) = Cr3::read();
let phys = level_4_table_frame.start_address();
let virt = physical_memory_offset + phys.as_u64();
let page_table_ptr: *mut PageTable = virt.as_mut_ptr();
&mut *page_table_ptr
}
|
只要能够得到第一个映射表就好办了,可以一级一级找到最开始的物理地址,这个过程就是内存映射,然后通过这种映射能够找到空闲的物理空间,从而为下一步的内存分配打好基础。
1
2
3
4
5
6
7
|
fn usable_frames(&self) -> impl Iterator<Item = PhysFrame> {
let regions = self.memory_map.iter();
let usable_regions = regions.filter(|r| r.region_type == MemoryRegionType::Usable);
let addr_ranges = usable_regions.map(|r| r.range.start_addr()..r.range.end_addr());
let frame_addresses = addr_ranges.flat_map(|r| r.step_by(4096));
frame_addresses.map(|addr| PhysFrame::containing_address(PhysAddr::new(addr)))
}
|
当建立完页表之后,就到了内存分配这个环节。
4. 内存分配(堆与栈内存的分配)
在计算机中有两种内存,stack & heap。一般说内存分配指的是堆内存分配,在计算机内存中,内存的分配如下图所示
 栈是向地址低的方向扩展,而堆则是向高的方向扩展,栈的操作速度比堆快,因为栈只有一个方向可以操作,而堆不一样了,堆可以有很多很多方向进行操作,因为堆是通过地址来访问的,同时还涉及到堆内存的分配以及回收,因此操作比栈慢。栈内存的分配比较简单,直接操作栈顶就可以了,通过出栈以及入栈实现数据的转移等等。而堆不一样,第一步去内存中寻找空闲的区域,第二步去将数据写入被分配的空间中,第三步是程序完成之后进行回收。那么栈与堆的区别在哪里? 数据分别很多种,最常见的是基本数据类型,这种数据类型是固定的,比如int、float等等,都是32位或者64位,但是有一种数据类型是不确定的,确定的类型是在程序编译期间就固定大小的,而有些类型是运行时分配,比如获取用户的输入,运行时大小变化的量,而这些量在程序编译期间是不知道的,这就是栈和堆最大的区别。
在x86_64系统中,内存空间是随机的,这是为了安全,如果是固定的,那就会给黑客带来可乘之机,具体的技术查阅Address space layout randomization。在我写的操作系统中,是固定大小的
栈是向地址低的方向扩展,而堆则是向高的方向扩展,栈的操作速度比堆快,因为栈只有一个方向可以操作,而堆不一样了,堆可以有很多很多方向进行操作,因为堆是通过地址来访问的,同时还涉及到堆内存的分配以及回收,因此操作比栈慢。栈内存的分配比较简单,直接操作栈顶就可以了,通过出栈以及入栈实现数据的转移等等。而堆不一样,第一步去内存中寻找空闲的区域,第二步去将数据写入被分配的空间中,第三步是程序完成之后进行回收。那么栈与堆的区别在哪里? 数据分别很多种,最常见的是基本数据类型,这种数据类型是固定的,比如int、float等等,都是32位或者64位,但是有一种数据类型是不确定的,确定的类型是在程序编译期间就固定大小的,而有些类型是运行时分配,比如获取用户的输入,运行时大小变化的量,而这些量在程序编译期间是不知道的,这就是栈和堆最大的区别。
在x86_64系统中,内存空间是随机的,这是为了安全,如果是固定的,那就会给黑客带来可乘之机,具体的技术查阅Address space layout randomization。在我写的操作系统中,是固定大小的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
pub const HEAP_START: usize = 0x_4444_4444_0000;
pub const HEAP_SIZE: usize = 100 * 1024;
pub fn init_heap(
mapper: &mut impl Mapper<Size4KiB>,
frame_allocator: &mut impl FrameAllocator<Size4KiB>,
) -> Result<(), MapToError<Size4KiB>> {
let page_range = {
let heap_start = VirtAddr::new(HEAP_START as u64);
let heap_end = heap_start + HEAP_SIZE - 1u64;
let heap_start_page = Page::containing_address(heap_start);
let heap_end_page = Page::containing_address(heap_end);
Page::range_inclusive(heap_start_page, heap_end_page)
};
for page in page_range {
let frame = frame_allocator
.allocate_frame()
.ok_or(MapToError::FrameAllocationFailed)?;
let flags = PageTableFlags::PRESENT | PageTableFlags::WRITABLE;
unsafe { mapper.map_to(page, frame, flags, frame_allocator)?.flush() };
}
unsafe {
ALLOCATOR.lock().init(HEAP_START, HEAP_SIZE);
}
Ok(())
}
|
开辟虚拟heap空间,然后使用MMU进行映射,将虚拟空间的页映射到真实物理地址的frames。然后在运行程序中就可以直接进行内存的分配,
1. 最简单的一种分配就是块分配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
impl BumpAllocator {
pub const fn new() -> Self {
BumpAllocator {
heap_start: 0,
heap_end: 0,
next: 0,
allocations: 0,
}
}
pub unsafe fn init(&mut self, heap_start: usize, heap_size: usize) {
self.heap_start = heap_start;
self.heap_end = heap_start + heap_size;
self.next = heap_start;
}
}
|
如图直接分配一个大块,但是当程序多容易造成浪费。

2. Linked List Allocator
链表方式的内存分配是最常见的也是相对来说比较容易理解的,核心思想就是将空闲空间通过链表来链接起来,分配的时候将free的空间从链表中除去,回收的时候添加到链表中。如图
 通过对链表的操作从而实现对内存的分配。
通过对链表的操作从而实现对内存的分配。
3. Fixed-Size Block Allocator
上述链表方式的内存分配也有缺点,那就是一旦在大的空闲内存空间分配一个小的空间,容易造成Internal fragmentation,因此需要一个更好的方法来进行内存分配。一个比较好的内存分配方式是固定开辟,也就是设定一个多个链表,每一个链表管理不同大小的固定空间,(For example, with block sizes of 16, 64, and 512 bytes, an allocation of 4 bytes would return a 16-byte block, an allocation of 48 bytes a 64-byte block, and an allocation of 128 bytes an 512-byte block.)
如图
 不同的内存分配方法具有不同的性能,没有一个内存分配是最好的,只有权衡,因此这个内存分配还有大量的工作可以探索。
不同的内存分配方法具有不同的性能,没有一个内存分配是最好的,只有权衡,因此这个内存分配还有大量的工作可以探索。
5. 线程 (todo)
6. 文件系统
计算机的一个大功能就与外部设备进行交互,计算机有一个外设组件互连标准与外设进行交互。常见的PCI卡包括网卡、声卡、调制解调器、电视调谐器和磁盘控制器等,另外还有USB和串列端口等端口。原本显卡通常也是PCI设备,但很快其频宽已不足以支持显卡的性能。PCI显卡现在仅用在需要额外的外接显示器或主板上没有AGP和PCI Express槽的情况。因此一个操作系统必须要有一个统一的方式操作PCI设备。根据文档,操作PCI设备是通过一些port进行操作的,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
impl ConfigRegister {
pub fn new(bus: u8, device: u8, function: u8, offset: u8) -> Self {
Self {
data_port: Port::new(0xCFC),
addr_port: Port::new(0xCF8),
addr: 0x8000_0000
| ((bus as u32) << 16)
| ((device as u32) << 11)
| ((function as u32) << 8)
| ((offset as u32) & 0xFC),
}
}
pub fn read(&mut self) -> u32 {
unsafe {
self.addr_port.write(self.addr);
self.data_port.read()
}
}
}
|
比如得到设备的名称以及id等等都是通过读写对应的端口实现的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
fn get_vendor_id(bus: u8, device: u8, function: u8) -> u16 {
let mut register = ConfigRegister::new(bus, device, function, 0x00);
register.read().get_bits(0..16) as u16
}
fn get_device_id(bus: u8, device: u8, function: u8) -> u16 {
let mut register = ConfigRegister::new(bus, device, function, 0x00);
register.read().get_bits(16..32) as u16
}
fn get_header_type(bus: u8, device: u8, function: u8) -> u8 {
let mut register = ConfigRegister::new(bus, device, function, 0x0C);
register.read().get_bits(16..24) as u8
}
|
8. 网络(todo)
当完成PCI之后,就可以直接使用PCI来控制网卡驱动,从而实现网络的功能。在本系统中,使用的网络驱动模块是RTL8139,在启动qemu时候需要在toml文件中添加如下的语句
1
2
|
[package.metadata.bootimage]
run-args = ["-nic", "model=rtl8139"]
|
然后在内核中就可以编写代码来驱动网卡,从而实现与网络的交互。
TCP三次握手
三次握手作为一个计算机面试常见的题目,是一个基本的知识。首先第一次握手是客户端发送一个特殊的报文给服务器,第二次握手是服务器返回一个特殊的报文给客户端,然后客户端再次发送请求报文,握手完成之后就是开始了信息的传递过程。
9. shell
编写shell是最简单的事情之一,因为shell就是实现各种命令,而各种命令是均是调用操作系统的内核函数实现的。shell是一个死循环,每次将用户输入命令调用即可。一个简单的shell环境是
1
2
3
4
5
6
7
|
if self.cmd.len() > 0 {
let line = self.cmd.clone();
self.history.push(line.clone());
self.history_index = self.history.len();
self.exec(&line);
self.cmd.clear();
}
|
而其中的exec就是执行各种用户的函数,比如实现date函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
pub fn main() {
let seconds = kernel::clock::realtime();
let nanoseconds = libm::floor(1e9 * (seconds - libm::floor(seconds))) as i64;
let date = OffsetDateTime::from_unix_timestamp(seconds as i64).to_offset(offset())
+ Duration::nanoseconds(nanoseconds);
let format = "%FT%H:%M:%S";
match time::util::validate_format_string(format) {
Ok(()) => {
print!("{}\n", date.format(format));
}
Err(e) => {
print!("Error: {}\n", e);
}
}
}
fn offset() -> UtcOffset {
UtcOffset::seconds(8 * 3600)
}
|
通过系统函数得到RTC然后根据时区去更改需要显示的数值即可
在我的系统中实现了3个简单的命令,分别是
- date
- sleep
- uptime
总结
写如此的一个操作系统是非常耗时的,但是每次写操作系统代码的时候就非常兴奋,因为每次编写都能够学到各种各样的系统知识,当完成到shell这一步,操作系统仍有很长的路要走,比如各种各样的命令实现如curl,而这个工程是非常巨大的,作为一个tiny-os,路到这里就差不多了,但是操作系统内核的学习远远没有结束。
参考