程序语言是给人读写的语言,如何将程序语言变成可执行的代码需要经过翻译。目前计算机语言分为两种派别1、解释器;2、编译器。其中解释器是边解释边执行,不需要将全部的代码一次性执行,经典的解释型语言有Python、Ruby,Perl, Matlab等等。而编译器则是将代码一次性编译成功然后执行,经典的编译型代码有C, C++, Java, Go, Rust等等,两者最大的区别在于速度以及执行方式,而从实现上来说解释器相对编译器要简单很多。这篇文章主要讲解了如何使用Rust语言来实现一个简单的解释器。为什么使用Rust,第一Rust是笔者最喜欢的语言之一,另外两个语言是Python 和 C。Rust被定义为系统级的编程语言,快,而笔者感觉Rust中最厉害的在于其匹配模式也就是match语法,简单来说
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
fn main() {
struct Foo {
x: (u32, u32),
y: u32,
}
// Try changing the values in the struct to see what happens
let foo = Foo { x: (1, 2), y: 3 };
match foo {
Foo { x: (1, b), y } => println!("First of x is 1, b = {}, y = {} ", b, y),
// you can destructure structs and rename the variables,
// the order is not important
Foo { y: 2, x: i } => println!("y is 2, i = {:?}", i),
// and you can also ignore some variables:
Foo { y, .. } => println!("y = {}, we don't care about x", y),
// this will give an error: pattern does not mention field `x`
//Foo { y } => println!("y = {}", y),
}
}
|
该例子来自于rust-by-example,可以发现能够支持强大的匹配,从而得到具体的内容。在编写解释器期间,需要大量的匹配,通过Rust这种语言特性能够减少大量的代码,从而实现快速实现功能。
概览
- 定义Token
- 实现lexer
- 实现parser(重点)
- 实现evaluator
- 扩展迷你解释器
1. 定义Token
第一步就是将人看懂的语言转换成对应有意义的Token,这个Token就是有意义的词,如编程语言中的If, else, new, 等等。而这些Token在Rust中很容易被实现,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#[derive(Debug, Clone, PartialEq)]
pub enum Token {
ILLEGAL,
EOF,
IDENT(String),
INT(i64),
BOOL(bool),
STRING(String),
ASSIGN,
PLUS,
MINUS,
BANG,
ASTERISK,
SLASH,
...
}
|
具体的代码实现在token.rs,得益于Rust强大的匹配模式,我们定义了IDENT(String),这是用来捕捉变量的一种方式,如let x = 3;,那么就会被翻译成
1
2
3
4
5
|
Token::LET,
Token::IDENT(String::from("x")),
Token::ASSIGN,
Token::INT(3),
Token::SEMICOLON,
|
是不是很简单!
2. 实现lexer
第一步只是定义了Token,那么如何将程序员写的语言转换成有意义的一个个Token,那么就需要lexer analysis操作。lexer analysis称之为词法分析,将字符序列转换为标记Token序列的过程。比如
1
2
3
4
5
|
if (5 < 10) {
return true;
}else {
return false;
}
|
对应的Token为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Token::IF,
Token::LPAREN,
Token::INT(5),
Token::LT,
Token::INT(10),
Token::RPAREN,
Token::LBRACE,
Token::RETURN,
Token::BOOL(true),
Token::SEMICOLON,
Token::RBRACE,
Token::ELSE,
Token::LBRACE,
Token::RETURN,
Token::BOOL(false),
Token::SEMICOLON,
Token::RBRACE,
|
因此需要一个算法来将所有的Token获取到。在这里使用读取每一个char,然后进行分析。
定义一个结构体来读取每一个char
1
2
3
4
5
6
|
pub struct Lexer<'a> {
input: &'a str,
pos: usize,
next_pos: usize,
ch: u8,
}
|
其中input是输入的字符串序列,pos指的是当前读取的索引,next_pos指的是下一个索引,ch指的是当前char。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
impl<'a> Lexer<'a> {
pub fn new(input: &'a str) -> Self {
let mut lexer = Lexer {
input,
pos: 0,
next_pos: 0,
ch: 0,
};
lexer.read_char();
lexer
}
fn read_char(&mut self) {
if self.next_pos >= self.input.len() {
self.ch = 0;
} else {
self.ch = self.input.as_bytes()[self.next_pos];
}
self.pos = self.next_pos;
self.next_pos += 1;
}
}
|
每运行一次read_char就会读取一个char,并将pos移到下一个位置。对于下一个token的赋值,需要通过不同的匹配来实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#[allow(dead_code)]
pub fn next_token(&mut self) -> Token {
let tok = match self.ch {
b'=' => {
if self.nextch_is(b'=') {
self.read_char();
Token::EQ
} else {
Token::ASSIGN
}
}
...
b'!' => {
if self.nextch_is(b'=') {
self.read_char();
Token::NOT_EQ
} else {
Token::BANG
}
}
...
b'[' => Token::LBRACKET,
b']' => Token::RBRACKET,
b':' => Token::COLON,
b'a'..=b'z' | b'A'..=b'Z' | b'_' => return self.read_identifier(),
b'0'..=b'9' => return self.read_number(),
b'"' => return self.read_string(),
0 => Token::EOF,
_ => Token::ILLEGAL,
};
self.read_char();
tok
}
|
在这里就可以看到Rust语言强大的匹配功能了。如果下一个token是常见的特殊字符,直接进行匹配,如果是ident、number、string,那么就跳到对应的方法,如果是其他就是非法字符。
而对应的read_identifier如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
fn read_identifier(&mut self) -> Token {
let pos = self.pos;
loop {
match self.ch {
b'a'..=b'z' | b'A'..=b'Z' | b'_' => {
self.read_char();
}
_ => {
break;
}
}
}
let literal = &self.input[pos..self.pos];
match literal {
"fn" => Token::FUNCTION,
"let" => Token::LET,
"true" => Token::BOOL(true),
"false" => Token::BOOL(false),
"if" => Token::IF,
"else" => Token::ELSE,
"return" => Token::RETURN,
_ => Token::IDENT(String::from(literal)),
}
}
|
这里读取的是变量,如果是关键字变量,那么就返回对应的关键字Token,如果是普通的变量,那么久直接返回Token::IDENT(String::from(literal)),。而number或者string同理,对应的代码在lexer中。
当完成Lexer之后,如果对以下的内容进行词法分析
1
2
3
4
5
6
|
let five = 5;
let ten = 10;
let add = fn(x, y)
{x + y;};
let result = add(five, ten);
!-/*5;
|
所得到的内容为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
Token::LET,
Token::IDENT(String::from("five")),
Token::ASSIGN,
Token::INT(5),
Token::SEMICOLON,
Token::LET,
Token::IDENT(String::from("ten")),
Token::ASSIGN,
Token::INT(10),
Token::SEMICOLON,
Token::LET,
Token::IDENT(String::from("add")),
Token::ASSIGN,
Token::FUNCTION,
Token::LPAREN,
Token::IDENT(String::from("x")),
Token::COMMA,
Token::IDENT(String::from("y")),
Token::RPAREN,
Token::LBRACE,
Token::IDENT(String::from("x")),
Token::PLUS,
Token::IDENT(String::from("y")),
Token::SEMICOLON,
Token::RBRACE,
Token::SEMICOLON,
Token::LET,
Token::IDENT(String::from("result")),
Token::ASSIGN,
Token::IDENT(String::from("add")),
Token::LPAREN,
Token::IDENT(String::from("five")),
Token::COMMA,
Token::IDENT(String::from("ten")),
Token::RPAREN,
Token::SEMICOLON,
Token::BANG,
Token::MINUS,
Token::SLASH,
Token::ASTERISK,
Token::INT(5),
Token::SEMICOLON,
|
这就是词法分析,仅仅是将每一个char进行整合,并没有各种策略在其中。
3. 实现parser(重点)
当完成了词法分析之后,就需要进行语法分析。语法分析是比较难的地方,整个过程设计到递归,因此需要对递归有一定的理解。parser主要的功能是将第二步得到的一个个词进行整理为语法树。如图所示
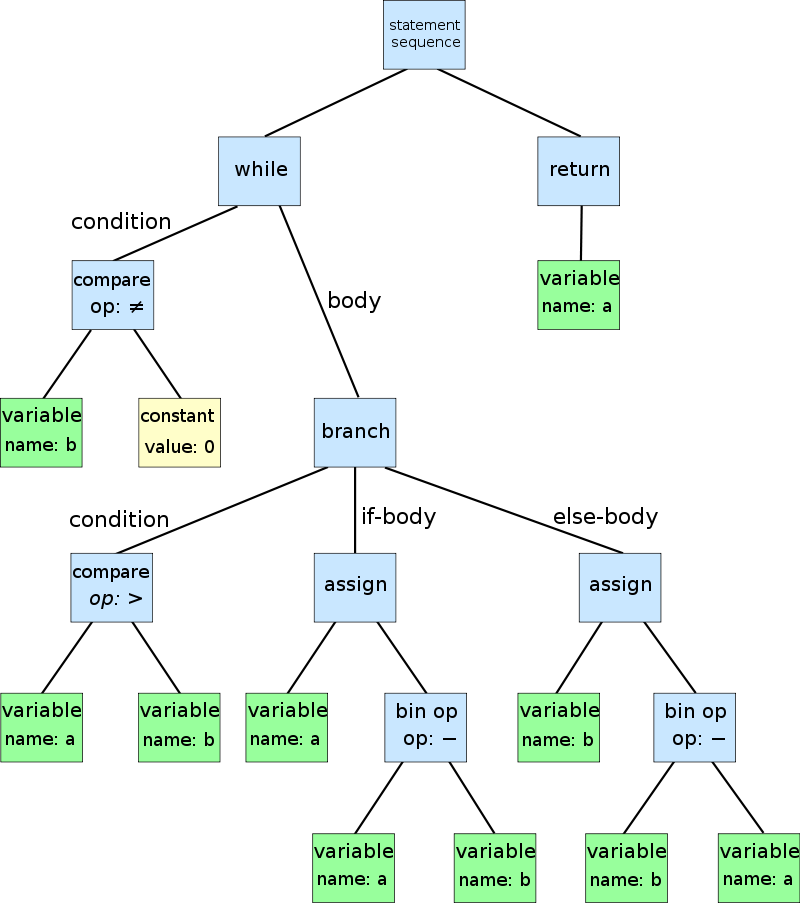 ,根据表达式优先级的高低,对词进行排序,优先级越高的就先执行,优先级低的就后执行。
比如下面的简单的4则运算
,根据表达式优先级的高低,对词进行排序,优先级越高的就先执行,优先级低的就后执行。
比如下面的简单的4则运算
 ,然后通过第4步的计算得到最终的结果。
,然后通过第4步的计算得到最终的结果。
parser let
语法如下
let <identifier> = <expression>;
let是最简单的语法,let后跟着一个identifier,然后是=, 最后是表达式,如果let之后不是identifier,那么就语法错误。
相对应的代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
fn parse_let_stmt(&mut self) -> Option<Stmt> {
match &self.next_token {
Token::IDENT(_) => self.next_token(),
_ => panic!(
"expected next token to be IDENT, got {:?} instead",
self.next_token
),
}
/// 下一个token应该是 identifier
let name = match self.parse_ident() {
Some(name) => name,
None => return None,
};
/// 再下一个token应该是 =
if !self.expect_next_token(Token::ASSIGN) {
return None;
}
/// 最后是一个表达式
let expr = expression;
/// 函数返回的是一个抽象语法树
Some(Stmt::Let(name, expr))
}
/// identifier处理
fn parse_ident(&mut self) -> Option<Ident> {
match self.current_token {
Token::IDENT(ref mut ident) => Some(Ident(ident.clone())),
_ => None,
}
}
|
当函数parse_let_stmt完成,返回的是一个抽象语法树,而这个语法树是一个let表达式
 ,而这个是在ast.rs中定义的
,而这个是在ast.rs中定义的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
pub enum Stmt {
Let(Ident, Expr),
}
pub enum Expr {
Ident(Ident),
Literal(Literal),
}
/// 字面意思
pub enum Literal {
Int(i64),
Bool(bool),
String(String),
Array(Vec<Expr>),
Hash(Vec<(Expr, Expr)>),
}
|
当进行let x = 5;返回的是一个这样的语法树
1
|
Stmt::Let( Ident(String::from("x")), Expr::Literal(Literal::Int(5)) ),
|
前面是一个变量,后面是一个表达式。
parser return
语法如下
return expression;
return也很简单,遇到return关键字就处理该语句。
1
2
3
4
5
6
7
8
9
10
11
12
|
fn parse_return_stmt(&mut self) -> Option<Stmt> {
self.next_token();
let expr = <expression>;
/// 如果遇到了; 那么就结束
if self.next_token_is(&Token::SEMICOLON) {
self.next_token();
}
/// 返回该表达式
Some(Stmt::Return(expr))
}
|
处理表达式 expression
表达式是计算机语言中最有意思的地方。表达式有很多种,以下都属于表达式
- 一元操作符
-5
!true
- 二元操作符
5+5
5 - 5
5 * 5
5 / 5
- 比较符
foo == foo
foo < bar
- 括号
5 * (5 + 5)
- 函数调用
add(3, 5)
max(5, add(5, 6))
add(x, y)
- if
if (10>5) {true} else {false}
处理表达式最简单的是自顶向下的方法,Top Down Operator Precedence是作者Vaughan Pratt于1973年提出的一种方法,遇到表达式就通过优先级来处理表达式。
首先一个整体框架为
1
2
3
4
5
6
7
|
fn parse_stmt(&mut self) -> Option<Stmt> {
match self.current_token {
Token::LET => self.parse_let_stmt(),
Token::RETURN => self.parse_return_stmt(),
_ => self.parse_expr_stmt(),
}
}
|
如果是let、return那么就处理各自的语句,如果两个都不是,那就是表达式,直接来处理表达式。
需要处理的表示有以下几类
- identifiers
- integer
- prefix op
- infix op
1. identifiers
如果遇到的是identifiers,那么有以下几种情况遇到这个identifiers
1
2
3
4
5
|
add(foo, bar);
foo + bar;
if (foo) {
}
|
如果是这几种情况就直接处理。
1
2
3
4
5
6
|
fn parse_ident(&mut self) -> Option<Ident> {
match self.current_token {
Token::IDENT(ref mut ident) => Some(Ident(ident.clone())),
_ => None,
}
}
|
2. integer
如果遇到的是数值类型的expression,也很简单直接处理
1
2
3
4
5
6
|
fn parse_int_expr(&mut self) -> Option<Expr> {
match self.current_token {
Token::INT(v) => Some(Expr::Literal(Literal::Int(v.clone()))),
_ => None,
}
}
|
3. prefix op
一元运算符有以下几种情况
-5
!foobar
5 + -9
同时具有优先级在其中,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
fn parse_prefix_expr(&mut self) -> Option<Expr> {
let prefix = match self.current_token {
Token::BANG => Prefix::NOT,
Token::MINUS => Prefix::MINUS,
Token::PLUS => Prefix::PLUS,
_ => panic!("not support prefix op"),
};
self.next_token();
match self.parse_expr(Precedence::PREFIX) {
Some(expr) => Some(Expr::Prefix(prefix, Box::new(expr))),
None => None,
}
}
|
而优先级的定义如下
1
2
3
4
5
6
7
8
9
10
|
pub enum Precedence {
LOWEST,
EQUALS, // ==
LESSGREATER, // > or <
SUM, // +
PRODUCT, // *
PREFIX, // -X or !X
CALL, // myFunction(x)
Index, // array[index]
}
|
越高的越优先处理,在代码的parser/mod.rs158行中,有一个这样的语句
1
|
while !self.next_token_is(&Token::SEMICOLON) && precedence < self.next_token_precedence()
|
这句话的意思是如果当前的优先级没有下一个token的优先级高,那么就处理当前的表达式,并产生一个抽象语法树。除了函数调用以及索引,一元表达式是最高的,因此优先处理。
4. infix op
中缀表达式是最常见的表达式,如
5 + 5
5 - 8
6 * 8
6 / 8
8 == 8
7 != 8
都属于中缀表达式,中缀表达式一般语法是
1
|
<expression> <infix op> <expression>
|
也就是左边是表达式,右边也是表达式,因此需要两边都处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
fn parse_infix_expr(&mut self, left: Expr) -> Option<Expr> {
let infix = match self.current_token {
Token::PLUS => Infix::PLUS,
Token::MINUS => Infix::MINUS,
Token::SLASH => Infix::DIVIDE,
Token::ASTERISK => Infix::MULTIPLY,
Token::EQ => Infix::EQUAL,
Token::NOT_EQ => Infix::NOTEQUAL,
Token::LT => Infix::LESSTHAN,
Token::GT => Infix::GREATERTHAN,
_ => panic!("do not support {:?}", self.current_token),
};
let precedence = self.current_token_precedence();
self.next_token();
match self.parse_expr(precedence) {
Some(expr) => Some(Expr::Infix(infix, Box::new(left), Box::new(expr))),
None => None,
}
}
|
在这里传入的是一个左表达式值,因为左值处理完了,处理的是右表达式,首先判断运算符是什么? 然后得到当前的符号的优先级,如果比下一个优先级低就处理下一个,否则直接返回,具体代码在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
fn parse_expr(&mut self, precedence: Precedence) -> Option<Expr> {
// prefix
let mut left = match self.current_token {
Token::IDENT(_) => self.parse_ident_expr(),
Token::STRING(_) => self.parse_string_expr(),
Token::INT(_) => self.parse_int_expr(),
Token::BANG | Token::MINUS | Token::PLUS => self.parse_prefix_expr(),
Token::LPAREN => self.parse_grouped_expr(),
Token::BOOL(_) => self.parse_bool_expr(),
Token::IF => self.parse_if_expr(),
Token::FUNCTION => self.parse_func_expr(),
Token::LBRACKET => self.parse_array_expr(),
Token::LBRACE => self.parse_hash_expr(),
_ => panic!("do not support {:?} token", self.current_token),
};
// infix
while !self.next_token_is(&Token::SEMICOLON) && precedence < self.next_token_precedence() {
match self.next_token {
Token::PLUS
| Token::MINUS
| Token::SLASH
| Token::ASTERISK
| Token::EQ
| Token::NOT_EQ
| Token::LT
| Token::GT => {
self.next_token();
left = self.parse_infix_expr(left.unwrap());
}
Token::LPAREN => {
self.next_token();
left = self.parse_call_expr(left.unwrap());
}
Token::LBRACKET => {
self.next_token();
left = self.parse_index_expr(left.unwrap());
}
_ => return left,
}
}
left
}
|
5. 小括号处理
小括号一般是用来处理表达式中优先级的问题。
(5+5)*2
直接进行处理,当处理到小括号最后一个token的时候,必须是右括号进行结束
1
2
3
4
5
6
7
8
9
|
fn parse_grouped_expr(&mut self) -> Option<Expr> {
self.next_token();
let expr = self.parse_expr(Precedence::LOWEST);
if !self.expect_next_token(Token::RPAREN) {
panic!("error");
} else {
expr
}
}
|
6. if 表达式
if (condition) <consequence> else <alternative>
其中condition是一个表达式,consequence是多个语句, alternative也是多个语句,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
fn parse_if_expr(&mut self) -> Option<Expr> {
if !self.expect_next_token(Token::LPAREN) {
panic!(
"execpt next token {:?} got {:?}",
Token::LPAREN,
self.next_token
);
}
self.next_token();
/// 处理条件语句
let cond = match self.parse_expr(Precedence::LOWEST) {
Some(expr) => expr,
None => return None,
};
if !self.expect_next_token(Token::RPAREN) || !self.expect_next_token(Token::LBRACE) {
return None;
}
/// 处理第一个分支
let consequence = self.parse_block_stmt();
let mut alternative = None;
if self.next_token_is(&Token::ELSE) {
self.next_token();
if !self.expect_next_token(Token::LBRACE) {
return None;
}
/// 如果有else分支就处理
alternative = Some(self.parse_block_stmt());
}
/// 最后返回If表达式
Some(Expr::If {
cond: Box::new(cond),
consequence,
alternative,
})
}
/// https://github.com/HadXu/rust-lang/blob/main/src/ast.rs
If {
cond: Box<Expr>,
consequence: BlockStmt,
alternative: Option<BlockStmt>,
},
|
7. function
function语法为
1
|
fn <parameters> <block statement>
|
其中parameters是以,分隔的多个参数,但是有可能有个参数都没有,因此在代码中需要实现这个逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
fn parse_func_expr(&mut self) -> Option<Expr> {
if !self.expect_next_token(Token::LPAREN) {
panic!("except {:?} but found {:?}", Token::LPAREN, self.next_token);
}
/// 处理函数参数
let params = match self.parse_func_params() {
Some(params) => params,
None => return None,
};
if !self.expect_next_token(Token::LBRACE) {
panic!("except {:?} but found {:?}", Token::LBRACE, self.next_token);
}
Some(Expr::Func {
params,
/// 处理函数体
body: self.parse_block_stmt(),
})
}
fn parse_func_params(&mut self) -> Option<Vec<Ident>> {
let mut params = vec![];
/// 如果下一个是右括号直接返回,无参数
if self.next_token_is(&Token::RPAREN) {
self.next_token();
return Some(params);
}
/// 得到每一个参数的ident
self.next_token();
match self.parse_ident() {
Some(ident) => params.push(ident),
None => return None,
}
/// 如果还有参数,就继续push进列表
while self.next_token_is(&Token::COMMA) {
self.next_token();
self.next_token();
match self.parse_ident() {
Some(ident) => params.push(ident),
None => return None,
}
}
if !self.expect_next_token(Token::RPAREN) {
panic!("except {:?} but found {:?}", Token::RPAREN, self.next_token);
}
Some(params)
}
|
8. 函数调用
1
|
<expression>(<comma separated expression>)
|
这是最简单的函数调用,抽象语法如下
1
2
3
4
|
Call {
func: Box<Expr>,
args: Vec<Expr>,
},
|
因此,只需要将函数名以及函数参数保存下来即可
1
2
3
4
5
6
7
8
9
10
|
fn parse_call_expr(&mut self, func: Expr) -> Option<Expr> {
let args = match self.parse_expr_list(Token::RPAREN) {
Some(args) => args,
None => return None,
};
Some(Expr::Call {
func: Box::new(func),
args,
})
}
|
到这里基本的抽象语法树完成。
4. 实现evaluator
这一步是解释器的最后一步求值。第三步虽然是重要的一步,但是仅仅完成了表达式的构建,并没有意义。比如1+1 抽象语法树也是infix<+, int(1), int(1)>,最终的程序是需要将这个计算出来的,也就是2,因此evaluator就是计算,就是求值,是有意义的一步。
一种方式是直接翻译抽象语法树,而另一种是转换为bytecode,然后求值。前者为解释器,后者为编译器。在本文中是解释器,通过遍历抽象语法树,求值得到最终的结果。
如果实现自己的解释器,首先需要一个值系统,用来表达Value,同时对value进行打印,如
1
2
3
4
5
6
7
8
9
10
11
|
pub enum Object {
Int(i64),
}
impl fmt::Display for Object {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
match *self {
Object::Int(ref value) => write!(f, "{}", value),
...
}
}
|
1. Integer
如果是int类型,直接赋值给语言对象
1
2
3
4
5
|
fn eval_literal(&mut self, literal: Literal) -> Object {
match literal {
Literal::Int(value) => Object::Int(value),
}
}
|
2. 前缀
前缀有3种,分别是
-
-
- !
直接进行求值即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
fn eval_not_op_expr(&mut self, right: Object) -> Object {
match right {
Object::Bool(true) => Object::Bool(false),
Object::Bool(false) => Object::Bool(true),
Object::NULL => Object::Bool(true),
_ => Object::Bool(false),
}
}
fn eval_minus_prefix_op_expr(&mut self, right: Object) -> Object {
match right {
Object::Int(value) => Object::Int(-value),
_ => panic!("unknown operator: -{}", right),
}
}
fn eval_plus_prefix_op_expr(&mut self, right: Object) -> Object {
match right {
Object::Int(value) => Object::Int(value),
_ => panic!("unknown operator: +{}", right),
}
}
|
3. 中缀
1
2
3
4
5
6
7
8
9
10
11
12
|
fn eval_infix_int_expr(&mut self, infix: Infix, left: i64, right: i64) -> Object {
match infix {
Infix::PLUS => Object::Int(left + right),
Infix::MINUS => Object::Int(left - right),
Infix::MULTIPLY => Object::Int(left * right),
Infix::DIVIDE => Object::Int(left / right),
Infix::LESSTHAN => Object::Bool(left < right),
Infix::GREATERTHAN => Object::Bool(left > right),
Infix::EQUAL => Object::Bool(left == right),
Infix::NOTEQUAL => Object::Bool(left != right),
}
}
|
整个求值系统本质上就是通过遍历抽象语法树,使用当前的语言将抽象语法树中的值求出来,然后赋值到新语言的系统当中。
4. 处理变量
在处理变量的时候需要注意,变量是存在于语言系统中的,也就是可以被访问,如果定义了一个变量,就需要将该值存在于环境变量中,便于接下来的使用,比如函数调用等等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
fn eval_stmt(&mut self, stmt: Stmt) -> Option<Object> {
match stmt {
Stmt::Let(ident, expr) => {
let value = match self.eval_expr(expr) {
Some(value) => value,
None => return None,
};
if Self::is_error(&value) {
Some(value)
} else {
let Ident(name) = ident;
self.env.borrow_mut().set(name, &value);
None
}
}
|
其中的env就是一个kv数据结构。
5. 函数调用
函数调用就是将之前的值绑定进行了利用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
fn eval_call_expr(&mut self, func: Box<Expr>, args: Vec<Expr>) -> Object {
let args = args
.iter()
.map(|e| self.eval_expr(e.clone()).unwrap_or(Object::NULL))
.collect::<Vec<_>>();
let (params, body, env) = match self.eval_expr(*func) {
Some(Object::Func(params, body, env)) => (params, body, env),
Some(Object::Builtin(expect_param_num, f)) => {
if expect_param_num < 0 || expect_param_num == args.len() as i32 {
return f(args);
} else {
panic!("wrong number of arguments");
}
}
Some(o) => panic!("{} is not valid function", o),
None => return Object::NULL,
};
if params.len() != args.len() {
panic!(
"wrong number of arguments: {} expected but {} given",
params.len(),
args.len()
)
}
let current_env = Rc::clone(&self.env);
let mut scoped_env = Env::new_with_outer(Rc::clone(&env));
let list = params.iter().zip(args.iter());
/// 对新的函数参数进行值绑定
for (_, (ident, o)) in list.enumerate() {
let Ident(name) = ident.clone();
scoped_env.set(name, o);
}
self.env = Rc::new(RefCell::new(scoped_env));
let object = self.eval_block_stmt(body);
self.env = current_env;
match object {
Some(o) => o,
None => Object::NULL,
}
}
|
5. 扩展
对解释器进行了一些其他功能的扩展,包括
- string支持
- 内置方法
- 数组
- hash
6. 支持wasm (todo)
使用wasm的支持将代码编译为wasm的代码
1
2
3
|
rustup target add wasm32-unknown-unknown
cargo build --bin wasm --release --target wasm32-unknown-unknown
wasm-gc target/wasm32-unknown-unknown/release/wasm.wasm web/src/monkey.wasm
|
参考
Let’s Build A Simple Interpreter.